Components in RASA NLU

In RASA, user messages is excecuted for every sequence of components. All components executed in RASA can be customized to meet any requirements in pipeline defined in config.yml file. We can even build our own (custom) component in RASA NLU.
Configurating the Right Components
Every components have different functions whether its for pre-processing text, intent classification, entity extraction, feature engineering, etc. A pipeline usually consist of three main function of components:
- Tokenization
Tokenization is the process of splitting messages/ text into word or tokens. Some built-in components of tokenization in - Featurization
Featurization is the process of feature engineering in the user messages. In RASA, we can either used pre-trained word embeddings or supervised embeddings (e.g count vectors). - Entity Recognition/ Intent Classification/ Response Selectors
We can choose any components we want to perform any of these task. We can even combine all the components related to these tasks depending on what we want to build.
One of model that is often being mentioned in RASA NLU is spaCy. SpaCy is pre-trained word-embedding models in many different languages from GloVe word embedding or fastText word embedding.
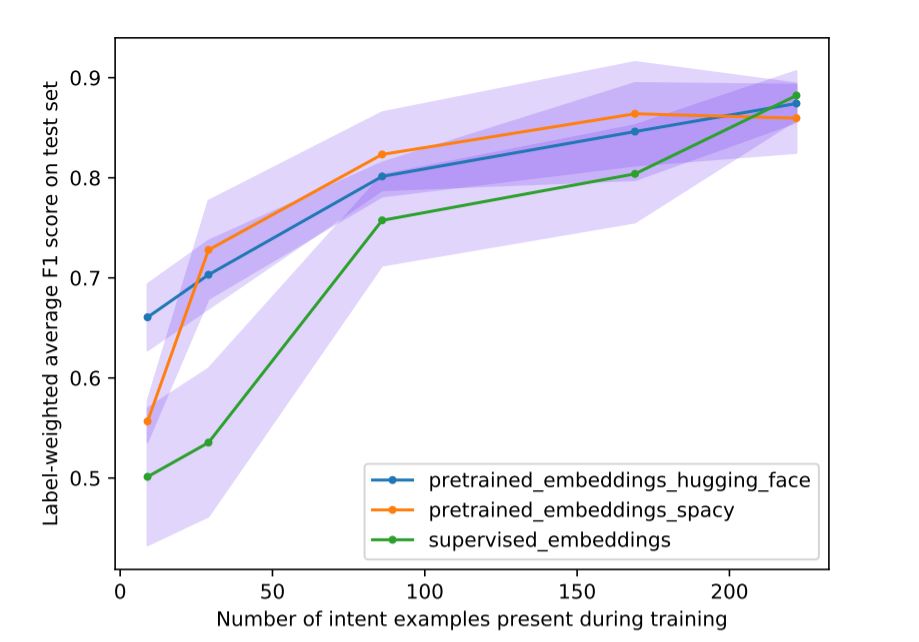
We tried to customize pipeline with spaCy model (pre-trained embeddings) and try to compare the results with the supervised embeddings.
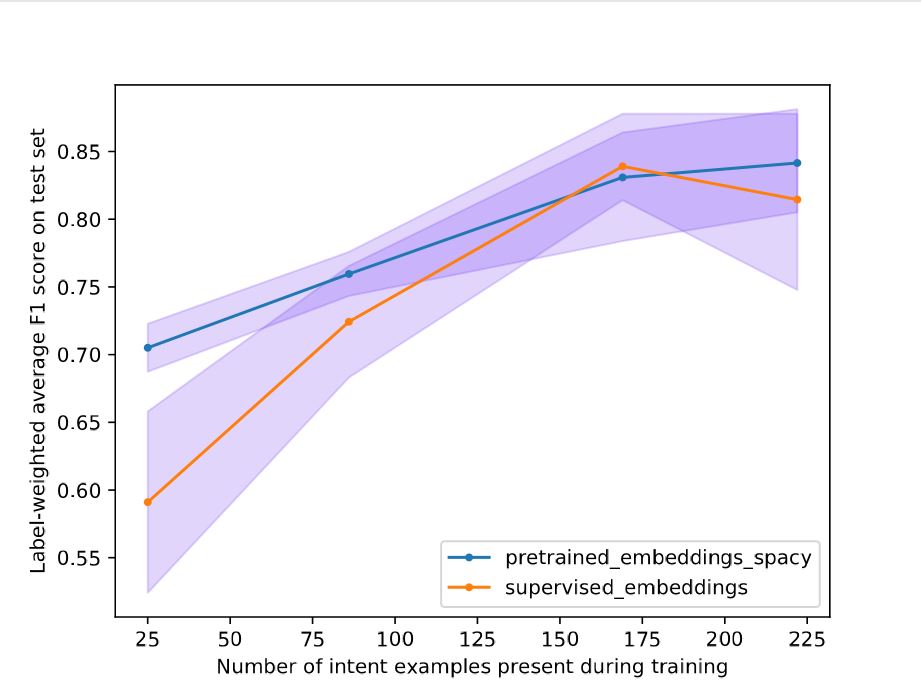
For more explanation on how to configurate pipeline with existing components in RASA, you can check out the video below:
Update:
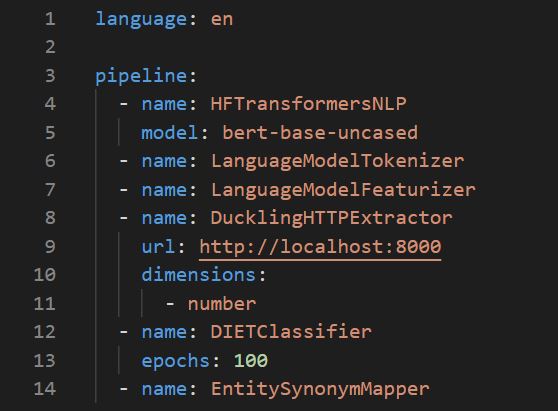
Here i tried to change the NLU configuration of the pipeline using other model, that is BERT.
Rasa provided the pipeline and configurations for BERT model using Hugging Face model in pipeline.
I’m using this Hugging Face configuration:
And the test result graphic is as shown below: